Overview
Example of general use of Vector autoregression analysis:
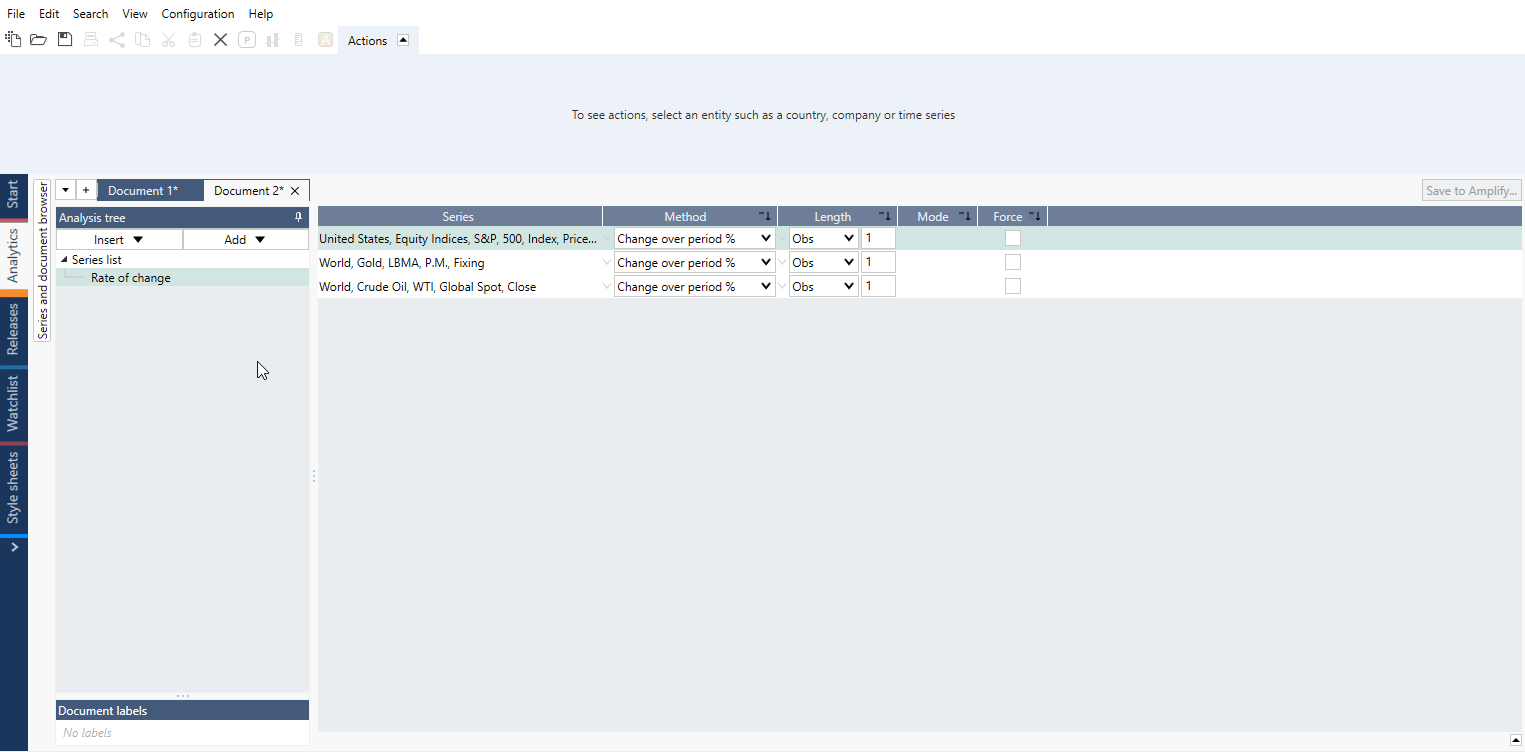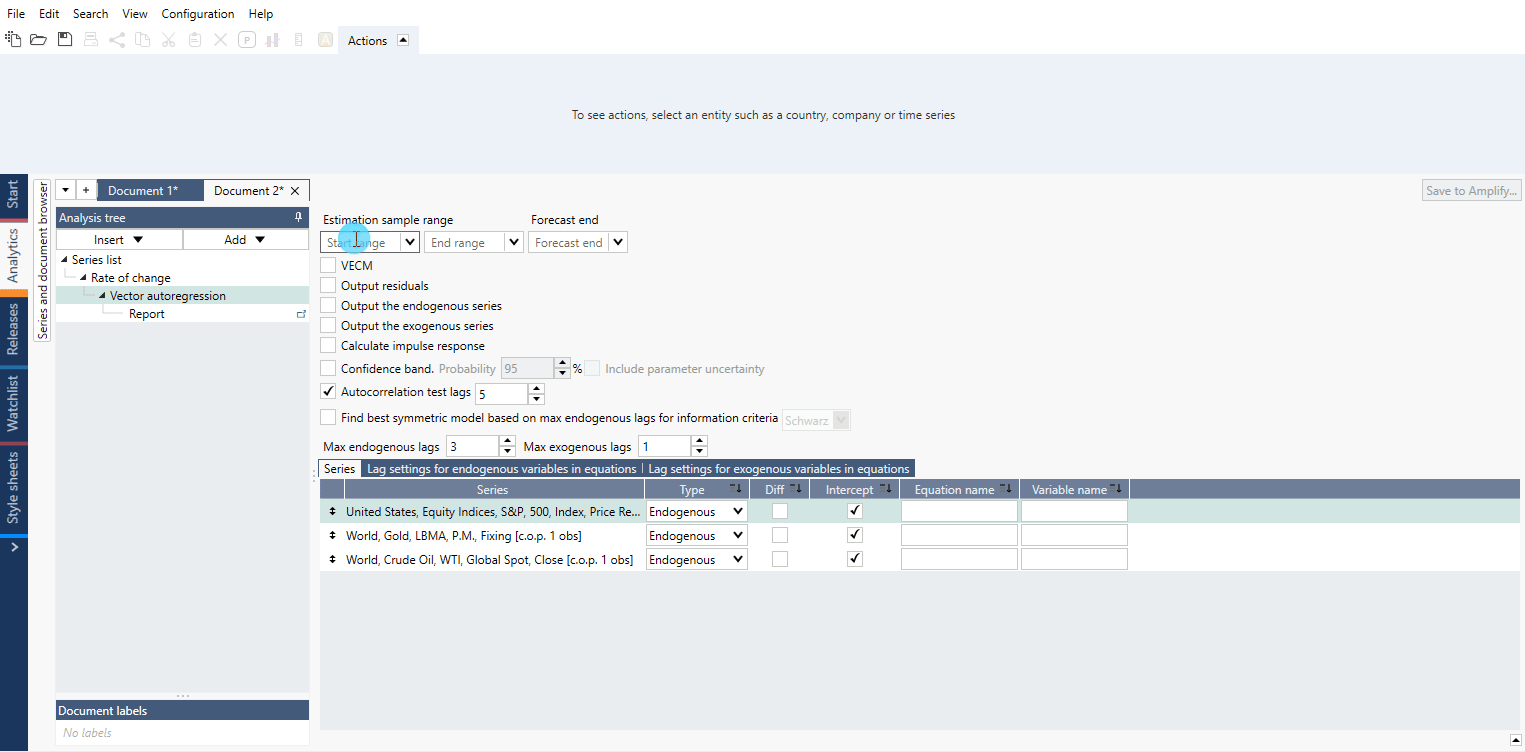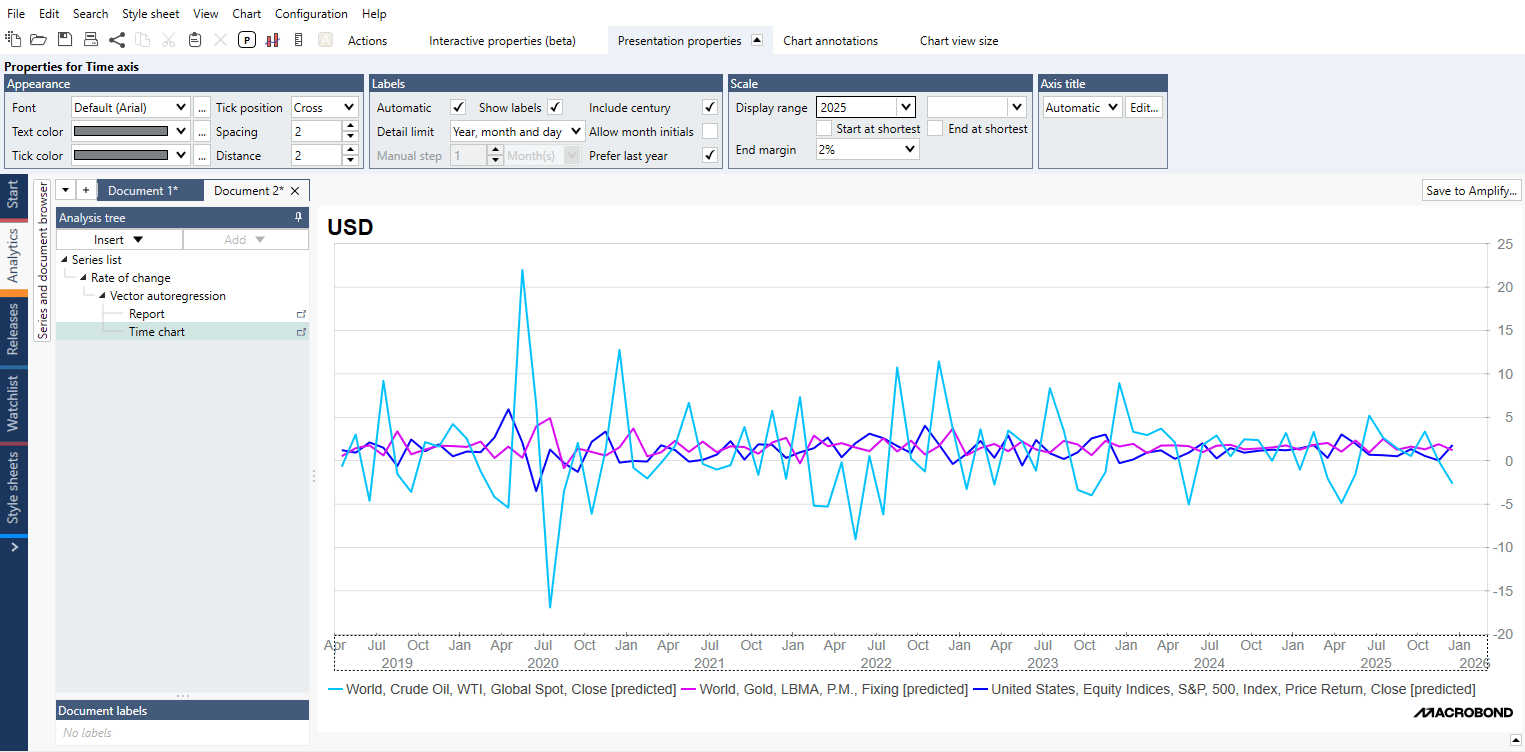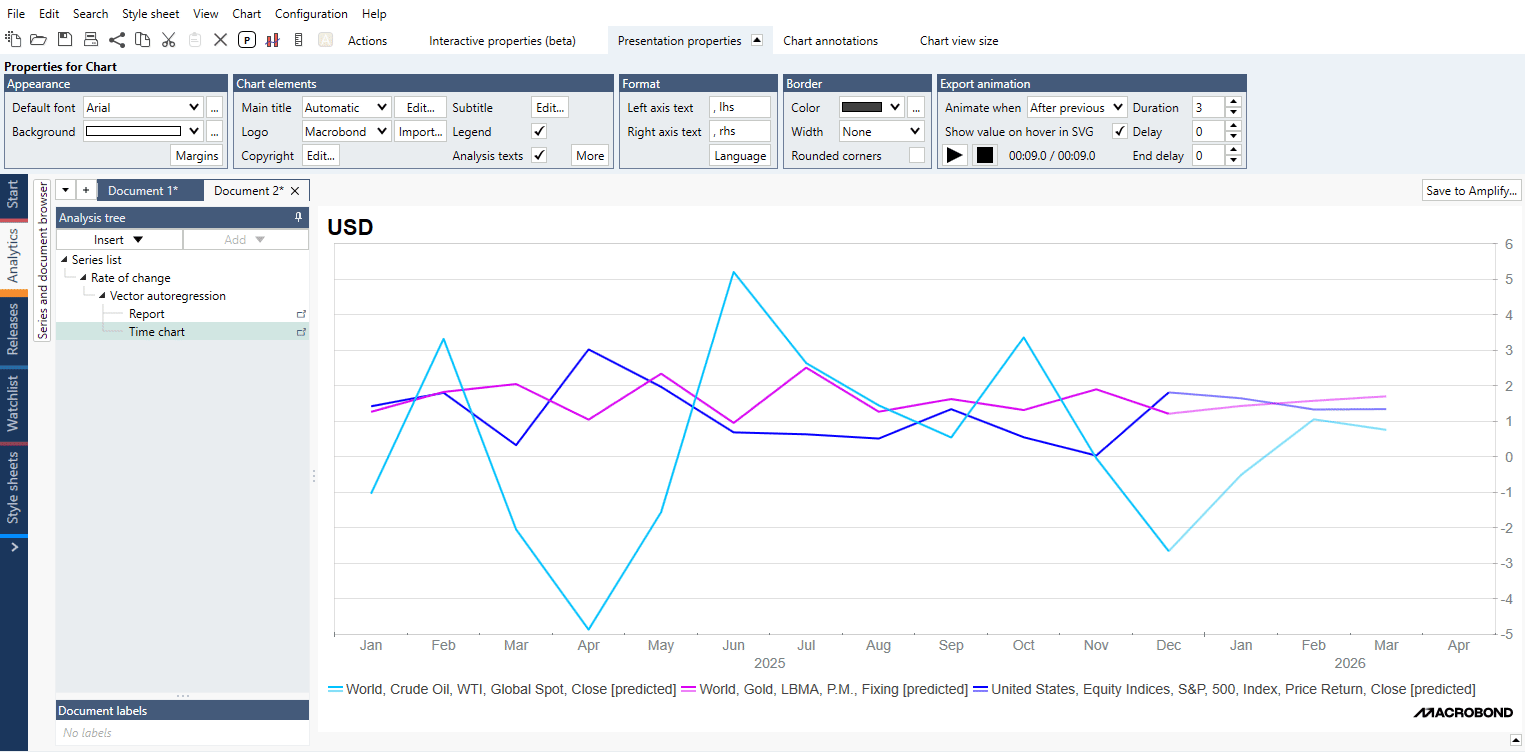
The Vector autoregression analysis (VAR) estimates the linear dependencies among a few series. The analysis can produce fitted values and forecasts for those series. In addition to estimating a given system, you can also automatically test different models and let the analysis pick the best one based on information criteria. The VAR analysis also allows for modelling of cointegrated variables. By calculating VECM you can estimate the speed at which a dependent variable returns to equilibrium after a change in other variables. Finally, the VAR analysis has a feature for calculating impulse response, the response of one variable to an impulse in another.
Estimation model
The main difference from regression analysis is that in VAR you have several dependent variables instead of one. A VAR can be thought of as a system of linear regressions, but the emphasis is on using lagged values of the dependent variables to model a set of variables. There is an equation for each variable that explains its evolution based on its own lags and the lags of other variables in the model.
The analysis yields a report that contains the estimated parameters of the system as well as several statistics that can be used as a test of the system's validity and stability. The estimation is made using all common valid observations for the model series in the selected estimation.
In the analysis, the dependent variables are called endogenous variables. There may also be exogenous variables. Such variables are only explanatory and are not modelled in the system. A model may be denoted as being of order p, called VAR(p), containing K endogenous variables. If there are 2 variables in a VAR (1) model, the system of equations can be written as:
The expression can be written in expanded form as:
The equations can thus be explicitly written as:
The present value of y depends on the intercept v, the lagged value of itself and the other variable, and the error term u. Each error term is supposed to be uncorrelated with all lags of itself and lags of the other error terms.
An arbitrary number of successive forecasts can be calculated, and you must specify an end date for the forecast calculation.
When a system contains exogenous variables, assume that these are included in the vector x together with their lags and possibly including lag 0 (contemporaneous variables) so that x contains s elements. The system of equations for a model called VARX (p, s) can then be written as:
When there are exogenous variables, forecasts can only be calculated as long as there is data available for all the exogenous variables. You might want to add forecasts to these variables before they are passed on to the VAR analysis.
For a symmetric system, where each equation contains the same explanatory variables and lags, OLS (ordinary least squares) is used as the estimation method. For asymmetric systems, GLS (generalized least squares) is used, which requires an iterative procedure. This is more computationally intense, and the system might not converge fast enough to find a solution for large systems.
Impulse Response
In order to examine a VAR system, an Impulse Response (IR) can be calculated between two given variables. While an econometrician may assume a system with several variables describes some economic relationship, it can still be interesting to isolate two of them and explore their particular dynamics, in one particular direction.
IR calculates the response of one variable to an impulse in another for some period later in time. IR has also been called dynamic multipliers, because the simplest way to compute them is to multiply the reduced form VAR-matrix by itself i times for a horizon i. The effect of past values for all coefficients in the system are used in the calculation, but we only look at the number for the accumulated effect that one variable has on another.
A way of understanding this is that by substituting the errors with a one where we investigate the impulse and zero everywhere else, an econometrician can trace this unit shock to the given variable at each time period.
IR calculation only makes sense between endogenous variables. The Macrobond application presently allows only unit residual IR. The Macrobond user can investigate the residuals prior to interpreting the IR results. For simplicity, the IR is represented as a time series, with values starting at the forecast date. The response function has the same unit as response variable, usually expressed in percentage points. The IR function outputted by VAR is in reduced or regular form.
Note we don't have the functionality to calculate error bars for the impulse response.
Cholesky's method for impulse response
A popular approach to IR has been Cholesky orthogonalization, where the model is first transformed by multiplying it with the Cholesky factor of the residual-covariance matrix, so that responses to orthogonal impulses are attained. This is a good idea as far as respecting the idea of isolated effects, but also requires the residuals to have finite variance (Hannsgen, 2010).
When using the Cholesky method the unit (y-axis) of the impulse response is the same as the unit of the response variable.
Ordering matters, however not in VECM (where you can drag series up & down) but on Series list.
VECM
The VAR analysis also allows for modelling of cointegrated variables. With this assumption, the variables on differenced form are explained by vectors on level form in addition to the usual VAR form. The rationale for this is that some variables co-move in the long run by the force of some linear process, while having other dynamics in the short run.
This is often illustrated by the 'drunk and his dog'. The drunk is walking home with great difficulty and often gets lost, but eventually makes it home. The dog is running around but only so far away from its owner, and they eventually both make it home. So, in the long run the two are always moving together, despite the fact that the walk is quite random and unrelated in the short run. Economic interpretations are plenty and allow for many relations at the same time for example long and short run interest rates, consumption and price level and consumption and investment.
The whole system is specified in Granger representation as:
where: is the low rank matrix where the cointegrating relations β are loaded onto each equation by α. The dimension of these matrices r is the cointegrating rank of the system. The “VAR part” contains the short-term variables and the coefficients are known as adjustment coefficients. This allows the model to capture some non-linearity that the regular VAR would miss.
The vectors are the error correcting vectors. They are not errors as in residuals, but refers to the long run effects compensating for what is not captured in the short run. If rank should be zero so that Pi = 0, the model is theoretically reduced to a VAR on change form, i.e., all variables differenced once. If Pi is full rank, the system reduces to a VAR on levels form. (Note that both of these cases tell us nothing about stability of the dynamic system which it represents.) Since these are not proper VEC-models the Macrobond application does not allow them and throws an exception if you try to model it (this includes the cases of automatic rank identification). Hence getting the VEC model right can be cumbersome, and it is not necessarily superiority to a regular VAR.
The rank statistics are determined by MHM (Mackinnon-Haug-Michelis, 1999) critical values. Each rank level of the matrix ΠΠ is tested. There are two options:
- The trace test at level r has a hypothesis so that and
- The maximum eigenvalue test at level r, on the other hand, tests the null hypothesis against
With the Macrobond application two approaches to VECM can be used: Johansen and Ahn-Rensel-Saikkonen. Johansen’s (1986) approach is solved for in a maximum likelihood scheme. It starts by identifying the cointegrating vectors. These are then subtracted from the original dependent variables. This reduces the system to a regular VAR which is solved using OLS. It is the best known and perhaps the most widely used VEC-model. Since the rank reduction of the matrix is done by means of eigendecomposition, this model may be viewed as employing noise reduction to clean up .
Ahn-Rensel-Saikkonen is based on least squares regression. It starts by estimating the whole system x.yz so that is full rank. Afterwards the proper rank reduction is made, decomposing to a lower rank, but without changing the short run coefficients . It is suggested in Brüggeman & Lütkepohl (2004) that this approach is more robust in small samples than Johansen.
Report
The VAR analysis automatically generates a report, which includes variety of statistical information.

Settings

Estimation sample range
Specify the limits of the estimation sample range. The default range will be the largest range where there is data for all the series.
Output residuals
When this option is selected a time series containing the residuals will be calculated.
Output the endogenous series
Select this option to include the endogenous series in the output.
Output the exogenous series
Select this option to include the exogenous series in the output.
Calculate impulse response
Select this option in order to calculate the impulse response of the specified length. Select in what equation the impulse should be applied and what variable.
Method
Unit - unit residual impulse response, applies a simple unit shock to the residuals without transforming them via the Cholesky decomposition, i.e., without any additional orthogonalization.
Cholesky - Cholesky’s method for impulse response.
Confidence band
Confidence bands for forecasts of each equation are computed using the VAR estimator covariance matrix. Since the VAR is ideally a stable linear dynamic system, the forecasted values are dynamically generated. This means that they converge toward some mean (zero if normalized). Therefore, the error bands must also converge to a constant value, an upper and lower bound, respectively. Because not much is known about the small sample properties about the Feasible Generalized Least Squares estimator used in the VAR, only asymptotic errors are computed. This makes the estimated error terms less reliable in estimations from short time series. It can be shown that the estimator variance of the FGLS is lower than or at least equal to that of standard OLS.
Autocorrelation test lags
Select this option in order to include a Portmanteau autocorrelation test in the report. Specify the number of lags to include. The number of lags should be larger than the highest number of lags of the endogenous or exogenous variables.
Max endogenous lags
Specify the maximum number of lags to include for the endogenous variables. You can further refine which lags to include in the model on the 'Lag settings for endogenous variables in the equations' tab.
Max exogenous lags
Specify the maximum number of lags to include for the exogenous variables. You can further refine which lags to include in the model on the 'Lag settings for exogenous variables in the equations' tab.
Find best model based on max endogenous lags for information criteria
Select this option to let the system automatically test what combination of symmetric lags are optimal based on the selected information criteria.
You can select the minimum and maximum number of lags of the endogenous variables to test and also the minimum and maximum of different lags (regressors) to include in each round of tests.
Select the setting 'Require stable process' in order to disqualify any model where the roots of the characteristic equation indicate that the model is not stable.
Type
Select if a series should be included in the model as an endogenous variable, exogenous variable.
Diff
By selecting Diff, the first order differences of the series will be calculated. The result will then be converted back to levels. First order of differences means that the series is transformed to "Change in value" (one observation) while expressing the result in levels.
Intercept
Select if the intercept should be included in the model for endogenous variables. This option is not available per variable for VECM.
Restrict to CE
In VECM, both trend and intercept can be restricted to the cointegrating relations. This means that they are treated as deterministic variables within , on level form. These occur either on level or change form, never both. The variables for intercept and trend are added by adding VECM in the configuration box.
Equation name
Optionally specify the name of the equation to be used in the report.
Variable name
Optionally specify the name of the equation to be used in the report.
VECM
Enables VECM.
Configuration
- Select method, Johansen or Ahn-Rensel-Saikkonen
- Include intercept adds an intercept variable
- Include linear trend adds a trend variable
Automatic cointegration test
Select whether to automatically find best cointegration rank or to enter it manually. The settings for automatic rank selection are described in the section Estimation model.
Examples
A model of five endogenous variables is defined in the Vector autoregression analysis. It is set to calculate a forecast for 1 month ahead. The model is a using three lags for each variable which is called a VAR (3) model.
The endogenous series are swap rates of maturities 10 years and 5 years for Sweden, Denmark, and the Euro area. The short run dynamics of these data are known to be dominated by simultaneous highly correlated shifts of all rates. The high correlation of short-term movements is explained by stable relation of levels of rates; the slope of yield curves.
Questions
How to add and use dummy variable in VAR model?
Create binary series (0/1 series) using conditions in the formula language or in-house series. Series should be added as an exogenous variable.
Examples of dummy variables:
quarter()=1 & year()=2020|quarter()=3 & year()=2020
Returns 1 if the observation is Q1 or Q3 for year 2020, 0 otherwise. Each quarter must have '& year()=2020' parameter, otherwise it will point to quarters in each year.
Counter()>=Date(2020, 1, 1)&Counter()<=Date(2022, 1, 1)
Returns 1 if the observation is between those dates, 0 otherwise.
Cop(usgdp, yearlength())<0
Returns 1 if the US GDP y/y growth rate is negative, 0 otherwise.