- Introduction
- Data Discovery
- Set up your data feed in the Macrobond management panel
- Use your Snowflake data feed
- Data Dictionary
Introduction
You can access any of Macrobond’s time series data into your Snowflake environment. The data feed is intended for production purposes with near real-time updates.
Here’s how it works:
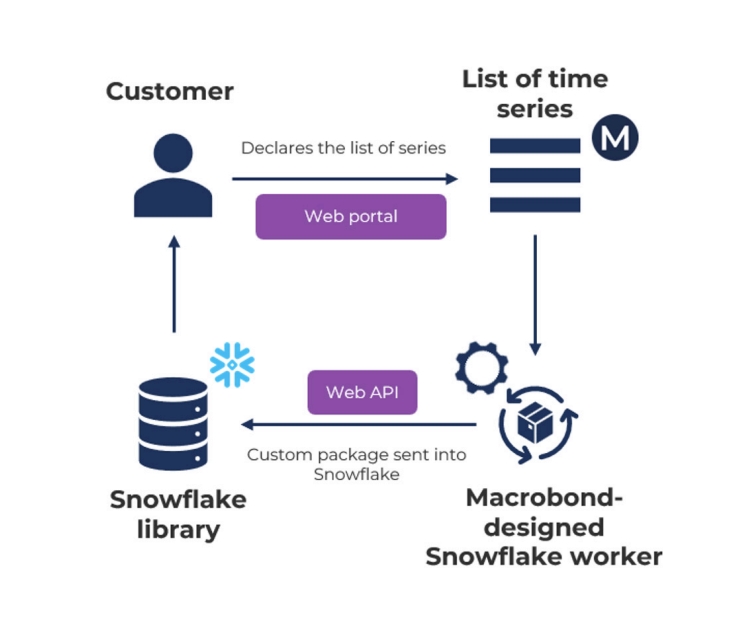
Data Discovery
The Snowflake data feed is used for production purposes only. Macrobond delivers the time series chosen by the consumer into their Snowflake environment. There are various options to explore the Macrobond database and find the time series to be delivered into Snowflake:
- Using Macrobond.net data catalogue. The Macrobond.net is a read only web portal that offers access to the tree structure and time series associated with every source included in the Macrobond base package. Users can use it to explore the coverage and start documenting the primnames (unique identifiers) of the time series they would like to consume via Snowflake.
- Using the Macrobond Analysis application. If you already subscribe to Core or Data+, the principles are the same as 1. above. If you subscribe to the desktop application, you have access to many more features including the analytics and sharing capabilities. Documenting a universe of time series via the Macrobond Analysis application can also be easier as it allows you to download the data in Excel or via API (Data+).
- Using the Macrobond Data Web API. Should you need to evaluate programmatically the time series data points, the Data Web API can also be used as a data feed product instead of being only an enabler to using the Snowflake data feed.
- Using Macrobond’s data team. You can express various parameters that fit into your requirements so that Macrobond’s data team can generate a list of time series by converting these parameters into Macrobond-defined metadata fields. This allows you to evaluate the full database at scale. To ensure you access your definite universe, our team will discuss with you your exact requirements.
Set up your data feed in the Macrobond management portal
Once you know which time series you would like to receive in Snowflake, or with the initial data set you are interested in, you can request the primnames through a dedicated portal provided by Macrobond.
The Macrobond team will provide access to this URL: https://feed.macrobond.com/login and send you via email your Username and Password.
Note that you can access the same portal through multiple team members to adjust the settings of your data feed in Snowflake.
Here is an overview of the key functions:

- Monitor your data feed properties
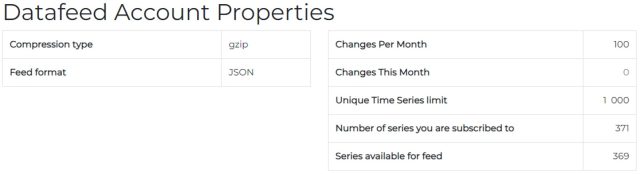
Your contractual allowance appears under “Unique Time Series limit”. You can use your feed during your subscription term (annual basis). You have an allowance of how many time series you can add or remove from your feed via the “Changes Per Month” counter, which corresponds to 10% of your total allowance. - Access your existing Subscription List and visualize or download the list of primnames you are subscribed to, including a flag denoting whether the series are feedable or not (compliance checks).
- Add time series to your data feed. You can add the primnames with a line break or decide to upload a list previously stored in a csv format.
- Remove time series from your data feed.
Use your Snowflake data feed
Once the time series are added into the Macrobond data feed management portal, the series are immediately delivered into your Snowflake environment. Note that depending on the volume of time series, this operation can take some time to load.
Time series updates are also provided into Snowflake with minimal latency as they are automatically pushed by Macrobond as soon as an entity received a complete update transaction in our backend system.
The Pay-As-You-Go Data feed in Snowflake provides access to a few tables and views. Data dictionary is available on the Snowflake listing: https://app.snowflake.com/marketplace/listing/GZSYZQKOHJ/macrobond-financial-macrobond-pay-as-you-go-data
Here is an overview of the schema. Columns that are repeated across multiple tables or views will be skipped once described in a table definition.
Data Dictionary
MAIN_ENTITY [Table]
It delivers the full dataset but should not be used straight away by the users. Instead, you should use either LATEST_ENTITY [View], derived from the MAIN_ENTITY table to obtain the latest version of your time series, or REVISION [Table] to obtain the vintages.
- PRIMNAME: unique identifier provided by Macrobond to identify a time series.
- METADATA: nest list of metadata fields for each time series containing lists or dictionaries.
- DATES: list of observation periods for the time series. Note that Macrobond uses the beginning of a period to denote the reference date. For instance, 2024-04-01 means “Q2 2024” in the case of a quarterly time series.
- OBSERVATION_VALUES: list of data points for the time series.
- ULID: a column intended to be used to join to REVISION (in conjunction with a PRIMNAME). This is a unique identifier for simultaneously transmitted time series (belonging to the same batch when loaded into Snowflake). A newer batch of uploads always increments this value. In a given batch of uploads, a given time series can appear only once.
- NUMBER_OF_REVISIONS: number of unique vintages for the selected time series. The underlying data can be consumed in the REVISION table.
- LAST_UPDATE: time stamp when the time series was fully delivered and accessible in Snowflake.
- FEED_QUEUE_INSERT_TIMESTAMP: time stamp when Macrobond-designed Snowflake worker added the time series to the insert queue as part of a loading batch.
REVISION [Table]
Some columns are already described in the previous table definition. New columns are:
- VINTAGETIMESTAMP: time stamp as to when this version of the time series containing data that could have been revision afterward it was made available in Macrobond.
Note that some time series have received a backfill to extend the point-in-time history directly from the source. As such, most of the time stamps prior to 2018 are arbitrary (as opposed to the date stamps).
To understand whether a time series received a backfill or not, you can refer to the time series metadata and look for fields: “RevisionHistorySource” and “RevisionHistorySourceCutOffDate”.
When both fields exist, the time series was backfilled. The spread between the cut off date and the “FirstRevisionTimeStamp” provides the magnitude of the backfill. Revisions post cut off date are all captured and stored by us, not by the source.
When VINTAGETIMESTAMP = null, it corresponds to the first unrevised version of a time series as Macrobond knows it. We do not know at which point in time this version was published, until there is a first revision, captured by the subsequent VINTAGETIMESTAMP = FirstRevisionTimeStamp in the metadata from when the information is known.
In summary, every time series capturing Revision History in Macrobond starts with a first vintage time stamps = null. - VINTAGEDATES: observation dates available as of the vintage time stamp.
- VINTAGEVALUES: observation points available as of the vintage time stamp.
SUBSCRIPTION [View]
You see the same information as you do in your data feed management portal. This is explained in 2. above. The table is updated once a day.
- PRIMNAME: requested primname. It can be an alias code.
- ACTUAL_CODE: primname in the Macrobond database.
- STATE: denotes the entity state. 0: active | 4: discontinued | -1: deleted
- AVAILABLE_FOR_FEED: 1: compliant | 0: non feedable. In case of non feedable time series, you can prove to Macrobond you have permission or a data license with the source and Macrobond can create a feedability exception on your account.
- LAST_UPDATE_IN_SNOWFLAKE: upload time stamp in Snowflake.
LATEST_ENTITY [View]
Derived from the MAIN_ENTITY table, this view provides the latest version of your time series. It is the equivalent to the latest vintage available for time series storing Revision History.